Book Review: “Lean Enterprise: How High Performance Organizations Innovate At Scale” (Jez Humble, Joanne Molesky, Barry O’Reilly)
PART I: ORIENT
Chapter 1 – Introduction
Starts explaining the importance of management and people and an approach in Toyota Production System. An alternative to command and control and other highlighted topics are:
A Lean Enterprise is primarily a human system:
- Pathological organizations: are characterized by large amounts of fear and threat. People often hoard information or withhold it for political reasons, or distort it to make themselves look better.
- Bureaucratic organizations: protect departments. Those in the department want to maintain their “turf”, insist on their own rules, and generally do things by the book – their book.
How organizations process information:
| Pathological (power-oriented) |
Bureaucratic (rule-oriented) |
Generative (performance – oriented) |
| Low cooperation |
Modest cooperation |
High cooperation |
| Messengers shot |
Messengers neglected |
Messengers trained |
| Responsibilities shirked |
Narrow responsibilities |
Risks are shared |
| Bridging discouraged |
Bridging tolerated |
Bridging encouraged |
| Failure leads to scapegoating |
Failure leads to justice |
Failure leads to enquiry |
| Novelty crushed |
Novelty leads to problems |
Novelty implemented |
The three gaps, and how to manage them:
|
Effects gap |
Knowledge gap |
Alignment gap |
| What is it? |
The difference between what we expect our actions to achieve and what they actually achieve |
The difference between what we would like to know and what we actually know |
The difference between what we want people to do and what they actually do |
| Scientific Management Remedy |
More detailed controls |
More detailed information |
More detailed instruction |
| Auftragstaktik remedy |
“Everyone retains freedom of decision and action within bounds” |
“Do not command more than is necessary or plan beyond the circumstances you can foresee” |
“Communicate to every unit as much of the higher intent as is necessary to achieve the purpose” |
| Directed opportunism remedy |
Give individuals freedom to adjust their actions in line with intent |
Limit direction to defining and communicating the intent |
Allow each level to define how they will achieve the intent of the next level up, and “backbrief” |
The key to the Principle of Mission is to create alignment and enable autonomy by setting out clear, high-level target conditions with an agreed time frame. This principle is applied in multiple contexts:
- Budgeting and financial management
- Program management
- Process improvement
Chapter 2 – Manage the Dynamics of the Enterprise Portfolio
This chapter explain the lifecycle of businesses and how companies can balance the exploration of new business models with the exploitation of proven ones.

Technology adoption lifecycle
Once the market has assimilated a disruptive new technology or idea, a whole range of product offerings gets spawned.
Exploring new opportunities and exploiting existing ones are fundamentally different strategies requiring different structure, competencies, processes, and mindset. It is hard to overemphasize this key point: management practices that are effective in the exploit domain will lead to failure if applied to exploring new opportunities – and vice versa. The difference between these two domains:
|
Explore |
Exploit |
| Strategy |
Radical or disruptive innovation, new business model innovation |
Incremental innovation, optimizing existing business model |
| Structure |
Small cross-functional multiskilled team |
Multiple teams aligned using Principle of Mission |
| Culture |
High tolerance for experimentation, risk taking, acceptance or failure, focus on learning |
Incremental improvement and optimization, focus on quality and customer satisfaction |
| Risk management |
Biggest risk is failure to achieve product / market fit |
A more complex set of trade-offs specific to each product / service |
| Goals |
Creating new markets, discovering new opportunities within existing markets |
Maximizing yield from captured market, outperforming competitors |
| Measure of progress |
Achieving product/market fi |
Outperforming forecasts, achieving planned milestones and targets |
Exploring New Ideas
Less than 50% of startups are alive five years after they start. The Lean Startup details a method for working in conditions of extreme uncertainty – to discover and operationalize new and potentially disruptive business models, and quickly discard those that will not work.
Every entrepreneur has a vision of their business. And for this vision to become reality, there are two key assumptions that must be tested:
- Values hypothesis: asks whether our business actually provides value for users by solving a real problem.
- Growth hypothesis: tests how fast we can acquire new customers and whether we have that.
Investing a fixed amount of time and money to investigate the economic parameters of and idea-be it a business model, product, or an innovation such as a process change-is an example of using optionally to manage the uncertainties of the decision to invest further. We limit our maximum investment loss (“downside”) on any individual idea, with the expectation that a small number of ideas will pay off big time, and offset or negate investment in those that did not.

The principle of optionality
The other part in this chapter is related to Enterprise Portfolio – balancing (using an economic model), matrix portfolio management (1. Emerging 2. Growth 3. Mature 4. Decline), managing a portfolio with the three horizons model (1. Current Business 2. High Growth Businesses 3. Growth Options).
PART II: EXPLORE
Chapter 3 – Model and Measure Investment Risk
Here is presented the principles and concepts that enable us to take a systematic approach to managing the risk of planned work, by gathering information to reduce uncertainty. Model Investment Risk using Business Case or Monte Carlo are discussed in this chapter to verify how useful they are in scenarios of uncertainty.
We should stop using the word “requirement” in product development, at least in the context of nontrivial features. What we have, rather, are hypotheses. In the case of business model and product innovation, the Lean Startup movement provide us with a framework for operating in conditions of extreme uncertainty:
- Do not spend a lot of time creating a sophisticated business model. Instead, design a simplified business model canvas with captures and communicates the key operating assumptions of your proposed business model.
- Gather information to determine if you have a problem worth solving.
- Then, design an MVP (minimum viable product)-an experiment designed to maximize learning from potential early adopters with minimum effort.
- Throughout this process, update the business model canvas based on what you learn from talking to customers and testing MVPs.
Traditional product lifecycle versus Lean Startup lifecycle:
|
Traditional project-planning process |
Lean Startup discovery process |
| What data do we have to make the investment decision? |
A business plan based on a set of untested hypotheses and assumptions, backed by case studies and market research |
Real data based on evidence complied from a working product or service tested with real customers |
| What happens next? |
We must create detailed requirements, if we haven’t already, and then starts a project to build, integrate, test, and finally release the system |
We already have a validated MVP which we can build upon immediately with new features and enhancements based on customer feedback |
| When do we find out if the idea is any good? |
Once the project is complete and the product or service is live |
We already have this evidence based on the data we have collected |
Principles for exploration
The OODA loop, a model of how humans interact with their environment which forms the basis of Boyd’s theory of maneuver warfare. OODA stands for observe, orient, decide, act, the four activities that comprise the loop.
Chapter 4 – Explore uncertainty of detect opportunities
In the chapter four, tools and techniques are shared to safely create and test hypotheses to solve real business problems identified and validated in our customer development process. Discovery is a rapid, time-boxed, iterative set of activities that integrates the practices and principles of design thinking and Lean Startup, used intensively at the beginning of the explore phase of a new initiative.
Creating a shared understanding (Dan Pink – Drive):
- Success requires a shared sense of purpose in the entire team
- People must be empowered by their leaders to work autonomously to achieve the team objectives
- People need the space and opportunity to master their discipline, not just to learn how to achieve “good enough”
With workshops, you can co-create ideas aligned to business goals. The process, starting with divergent thinking until convergent thinking can generate multiple ideas for discussion and debate.

Structured exploration with divergent and convergent thinking
The Business Model Canvas can share the understanding about business problem to inform the Business Plan. It includes nine essential components of an organization’s conceptual business model – customer segment, value proposition, channels, activities, resources, partnerships, cost and revenue.

Business Model Canvas
In this chapter, also is covered MVPs and how to accelerate experimentation with them. Cagan defines an MVP “the smallest possible product that has three critical characteristics: people choose to use it or buy it; people can figure out how to use it; and we can deliver it when we need it with the resources available-also known as valuable, usable and feasible”.
 Minimum Viable Product: build a slice across instead of one layer at a time
Minimum Viable Product: build a slice across instead of one layer at a time



An example set of types of MVPs
Chapter 5 – Evaluate the product/market fit
This chapter discuss how to identify when a product/market fit has been achieved and how to exit the explore stage and start exploiting our product with its identified market. Also, how to use customized metrics to understand whether we are achieving measurable business outcomes while continuing to solve our customers problems by engaging them throughout our development process.
Some examples of vanity metrics and corresponding actionable metrics:
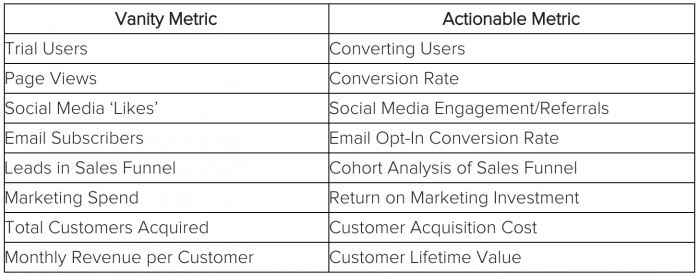 Examples of vanity versus actionable metrics
Examples of vanity versus actionable metrics
 Example innovation scorecard
Example innovation scorecard
The pirate metrics helps you to model any service-oriented business. Measuring pirate metrics for each cohort allows you to measure the effect of changes to your product or business model, if you are pivoting. The Votizen’s pirate metrics represents the effect of incremental change and pivots.

A story map can help you to tell the narrative of the Runway of our vision. Can be used to plan e prioritize by visualizing the solution as a whole. It provides an effective means to communicate the narrative of our solution to engage the team and wider stakeholders and get their feedback.

A user story map
The five critical enablers of growth when transitioning from explore to exploit are:
- Market
- Monetization model
- Customer adoption
- Forget “big bang” launches
- Team engagement
PART III: EXPLOIT
Chapter 6 – Deploy Continuous Improvement
In most enterprises, there is a distinction between the people who build and run software systems and those who decide what the software should do and make the investment decisions. Ultimately, we aim to remove this distinction. In high performance organizations today, people who design, build, and run software-based products are an integral part of business.
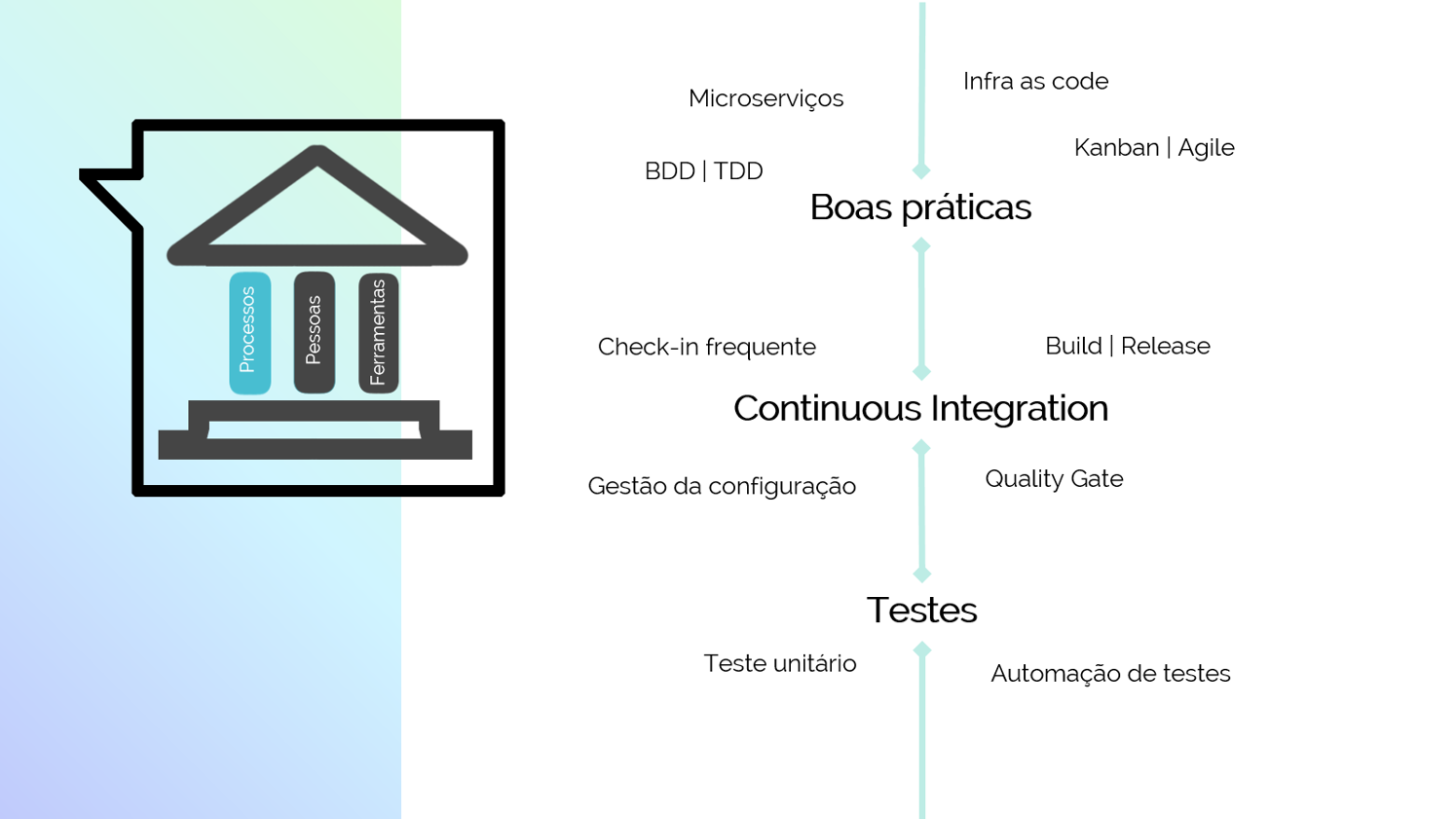
In this chapter is described how to achieve the balancing (the work we do to improve our capability against delivery work that provides value to customers) at program and value stream levels, by putting in place a framework called Improvement Kata. The other part, covers practices in CI/CD as branching versus trunk-based development and other. For more details, I recommend to access my blog.
A good example, in the HP LaserJet Firmware Case Study, we can see how allocating costs to the activities the team is performing.
| % of costs |
Activity |
| 10% |
Code integration |
| 20% |
Detailed planning |
| 25% |
Porting code between version control branches |
| 25% |
Product support |
| 15% |
Manual testing |
| ~5% |
Innovation |
The Improvement Kata needs to be first adopted by the organization’s management, because it’s a management philosophy that focuses on developing the capabilities of those they manage, as well as on enabling the organization to move towards its goals under conditions of uncertainty. There are four stages that we repeat in a cycle:
 The Improvement Kata
The Improvement Kata
- Understand the direction: derived from the vision set by the organization’s leadership.
- Grasp the current condition: after the direction, we incrementally and iteratively move towards it at the process level.
- Establish the next target condition: as we continuously repeat the cycle, we reflect on the last step taken to introduce improvement.
- Iterate toward the target condition
Three years after the initial measurements (in HP LaserJet case), a second activity-accounting exercise offered a snapshot of the results the FutureSmart team had achieved with their approach:
| % of costs |
Activity |
| 2% |
Continuous integration |
| 5% |
Agile planning |
| 15% |
One main branch |
| 10% |
Product support |
| 5% |
Manual testing |
| 23% |
Creating and maintaining automated test suites |
| ~40% |
Innovation |
Chapter 7 – Identify value and increase flow
Most enterprises are drowning in a sea of overwork, much of which provides little value to customers. In the previous chapter was showed how to implement a program-level continuous improvement strategy to improve productivity and quality and reduce costs. In this chapter, the purpose is showing how the five lean principles can be adopted to reduce the cycle time, increasing quality and return on investment.
In high-performing organizations, leadership and management has a sharp focus on the value the organization is creating for its customers.
The value stream map helps to reflect the current condition in a determined product or service we want to evaluate. This exercise must gather people from every part of organization involved in the value stream.
 Outline of a value stream map showing process blocks
Outline of a value stream map showing process blocks
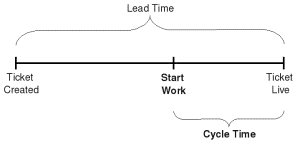
After concluded, we record three key metrics:
- Lead time: the time from the point a process accepts a piece of work to the point it hands that work off to the next downstream process
- Process time: the time it would take to complete a single item of work if the person performing it had all the necessary information and resources to complete it and could work uninterrupted
- Percent complete and accurate (%C/A): the proportion of times a process receives something from an upstream process that it can use without requiring work
Also is presented Kanban concepts to share a comprehensive way to manage the flow of work:
- Visualize workflow (creating a board)
- Limit WIP (work in progress)
- Define classes of service (for different types)
- Create a pull system (by agreeing on how work will be accepted into each process block when capacity becomes available)
And a Cost of Delay – a framework for decentralizing economic decisions, to identify and prioritize the work with the highest opportunity cost.

How do we prioritize Tasks A and B with Cost of Delay?
Chapter 8 – Adopt Lean Engineering Practices
“Cease dependence on mass inspection to achieve quality. Improve the process and build quality into the product in the first place”. W. Edwards Deming.
In this chapter there are important concepts to allow the organizations deploy new releases in production frequently, necessary to test ideas with real users and enable effective innovation process (learn and update based on feedback). For more details from other concepts like continuous integration, test automation, continuous deliver and deployment pipeline, access my blog.
 Deployment g-forces
Deployment g-forces
Chapter 9 – Take an Experimental Approach to Product Development
Up to now, the others chapters show how to improve the speed at which can deliver value to customer. In this chapter, the focus is to discuss alignment – how to use capabilities we have developed to make sure we are building the right things for customers, users, and our organization.
So, concepts as creating hypothesis, hypothesis-driven development and user research are described to focus on the outcomes we wish to achieve, rather than solutions and features.

Different types of user research
Also for more details, please visit my blog.
Chapter 10 – Implement Mission Command
The organizational and architectural concerns are often the biggest barriers to executing the strategy for moving fast at scale based on the principles of Mission Command (described in Chapter 1). Amazon has a famous memo to technical staff directing them to create a service-oriented architecture:
- All teams will henceforth expose their data and functionality through service interfaces
- Teams must communicate with each other through these interfaces
- There will be no other form of interprocess communication allowed. The only communication allowed is via service interface calls over the network
- It doesn’t matter the technology they use. HTTP, Corba, Pubsub, custom protocols.
- All services interfaces, without exception, must be designed from the ground up to be externalizable
- Anyone who doesn’t do this will be fired
A key principle of service-oriented architecture (SOA) is decomposing systems into components or services. Each component or service provides an interface (also known as an API – application programming interface) so that other components can communicate with it.
Here are some strategies enterprises have successfully applied to create autonomy for individual teams:
- Give teams the tools and authority to push changes to production
- Ensure that teams have the people they need to design, run and evolve experiments
- Ensure that teams have the authority to choose their own toolchain
- Ensure teams do not require funding approval to run experiments
- Ensure leaders focus on implementing Mission Command
 Example of traditional enterprise organization
Example of traditional enterprise organization
 Product teams working together, with a service layer for performing deployments
Product teams working together, with a service layer for performing deployments
Creating small, autonomous teams makes it economic for them to work in small batches. When done correctly, this combination has several important benefits:
- Faster learning, improved customer service, less time spent on work that does not add value
- Better understanding of user needs
- Highly motivated people
- Easier to calculate profit and loss
PART IV: TRANSFORM
Chapter 11 – Grow an innovation culture
Culture is the most critical factor in an organization’s ability to adapt to its changing environment. The main topics in this chapter are:
- Model and measure your culture: important to consider layers of organizational culture
- Artifacts: visible, observable aspects of culture such as organizational structures and processes, and how people dress and behave. Hard to decipher.
- Espoused values: strategies, goals, philosophies, such as the “value statements” you find in the company lobby
- Underlying assumptions: unconscious beliefs, perceptions, thoughts, feelings (which ultimately govern values and behavior)
- Change your culture: Old and new approaches to cultural change – Shook offers his own interpretation of Schein’s model, showing how people normally approach cultural change in contrast to the approach taken at NUMMI.
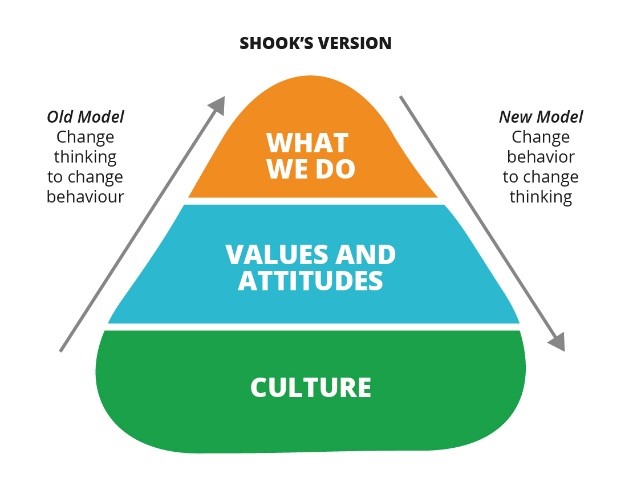
- Make it safe to fail
- There is no talent shortage: Dweck’s two mindsets, showed through a series of experiments that our mindset determines how you decide your goals, how to react to failure, what are our beliefs about effort and strategies, and what is our attitude towards the success of others.

- How Google recruits

- Growing talent: there are many ways in which enterprises can invest in people
- Help employees create and update personal development plans
- Separate performance reviews from compensation reviews
- Facilitate regular feedbacks
- Give employees access to training funds
- Give employees time to pursue their own goals
- Eliminate hidden bias: the effects of implicit gender bias on hiring. Here is a selection of strategies that haven proven useful
- Ensure equitable pay
- Create target conditions for recruitment and promotion
- Monitor tenure, rate of advancement and job satisfaction
- Regularly review policies, interactions and HR processes

Chapter 12 – Embrace Lean Thinking for Governance, Risk and Compliance
The chapter is to guide you through the maze that is GRC (Governance – Risk – Compliance), particularly as it relates to managing the concepts and practices required to be a lean enterprise. Governance is about keeping our organization in course. It is the primary responsibility of the board of directors, but it applies to all people and other entities working for the organization. It requires the following concepts and principles to be applied at all levels:
- Responsibility
- Authority and accountability
- Visibility
- Empowerment
- Risk management and compliance
Apply Lean Principles to GRC processes: visualizing the value stream, increasing feedback, amplifying learning, empowering teams, reducing waste and delays, limiting work in process, making small incremental changes, and continuously improving to achieve better outcomes.
Good Governance requires everyone to focus on discovering ways to improve value and provide accurate information on which to base our decisions. We start with leadership and direction from the Board and Executives, and rely the ability of employees to embrace their responsibility to make good decisions at work. A culture of openness, trust, and transparency is required for good governance.
Chapter 13 – Evolve Financial Management to drive Product Innovation
Centralized budgeting process are typically used to plan, forecast, monitor and report on the financial position and overall performance of an organization. However, the traditional annual budget cycle can easily:
- Reduce transparency
- Remove decision from the people doing the work
- Direct costs away from value creation
- Measure performance by the ability to please the boss or produce output

Approaches to achieving the goals of budgeting
The Dynamic Resource Allocation creates more frequent checkpoints for funding decisions, and each decision has less risk associated with it. All decisions are based on the empirical evidence, so they become easier to make. When done correctly, access to funding expands to more teams, gets more frequent, has less associated risk, and brings better results. We thus encourage more innovation and reduce financial risk associate with large initiatives.
 Dynamic resource allocation
Dynamic resource allocation
In the other part, the chapter describe:
- Avoid using budgets as the Basis for performance measurement: bonuses and rewards for good bottom-line financial results work better when they are shared equally. Working teams will eventually cripple the organization by inertia and subterfuge when their contributions are not acknowledged and rewards are based on a process perceived as unfair.
- Stop basing business decisions on CAPEX versus OPEX: there are tax advantages and positive financial impacts from reporting organization expenditures appropriately in these different buckets, so a lot of attention is paid to it.
- Modify your IT Procurement Processes to gain greater control over value delivery: this painful, highly detailed contractual process has several negative side effects
- It’s a poor way to manage the risks of product development
- It favors incumbents
- It favors large service providers
- It inhibits transparency
- It is inaccurate
- It ignores outcomes
Chapter 14 – Turn IT into a competitive advantage
This chapter is discussed some strategies to increase the responsiveness of IT to changing business needs, improve the stability of IT services, and reduce the complexity of our IT systems and infrastructure.
Rethinking the IT Mindset: IT has historically been seen as a cost center and an internal enabler of the business, not a creator of competitive advantage. In the 2014 State of DevOps Report, over 9,000 people worldwide were polled about what creates high-performance organizations, whether IT does in fact matter to the business, and what factors impact the performance of IT departments.
 What business leaders think about the business-IT relationship
What business leaders think about the business-IT relationship
The practices most highly correlated with high IT performance (increasing both throughput and stability) are:
- Keeping systems configuration, application configuration, and application code in version control
- Logging and monitoring systems that produce failure alerts
- Developers breaking up large features into small, incremental changes that area merged into trunk daily
- Developers and operations regularly achieving win/win outcomes when they interact
If we want to compete in a world of ever shorter product cycles, central IT needs to be business unit’s trusted partner, not an order-taking cost center. In turn, IT needs to achieve higher levels of throughput while improving stability and quality and reducing costs. The complexity of existing enterprise IT environments, combined with the amount of planned and unplanned work that must be done to keep them running, are the chief barriers to achieving these outcomes.
Chapter 15 – Start where you are
The biggest barrier to success in changing the way you work is a conviction that your organization is too big or bureaucratic to change, or that your special context prevents adopting the particular practices we discuss. Always remember that each person, team, and business that started this journey was unsure of what paths to take and how it would end. The only accepted truth was that if they failed to take action, a more certain, negative ending lay ahead.
The only path to a culture of continuous improvement is to create an environment where learning new skills and getting better at what we do is considered valuable in its own right and is supported by management and leadership, thus reducing learning anxiety. We can use the Improvement kata (presented in chapter 6) to create this culture and drive continuous improvement.
 Continuous evolution and adaption to change
Continuous evolution and adaption to change
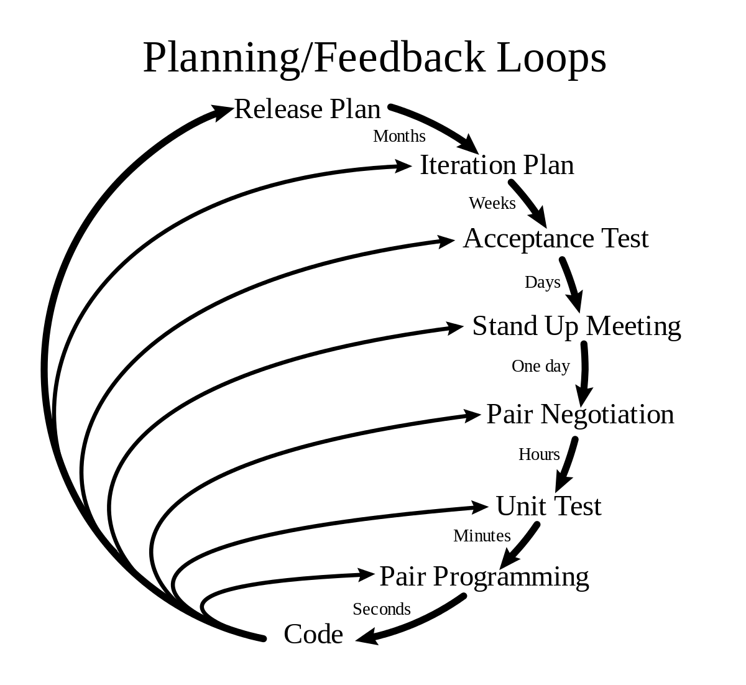
The process of creating alignment and consensus between levels is critical. In strategy deployment, this process is described as catchball, a word chosen to evoke a collaborative exercise. The target conditions from one level should not be transcribed directly into the direction for teams working at the level below. Catchball is more about translation of strategy, with “each layer interpreting and translating what objectives from the level above mean for it”.
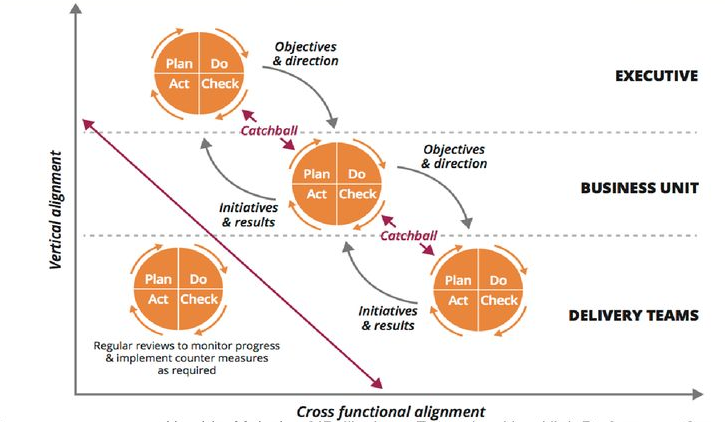
Using catchball to drive strategic alignment of objectives and initiatives
Begin your journey: use the following principles for getting started:
- Ensure you have a clearly defined direction
- Define and limit your initial scope
- Pursue a high-performance culture of continuous improvement
- Start with the right people
- Find a way to deliver valuable, measurable results from early on
Creating a resilient, lean enterprise that can adapt rapidly to changing conditions relies on a culture of learning through experimentation. For this culture to thrive, the whole organization must be aware of its purpose and work continuously to understand the current conditions, set short-term target conditions, and enable people to experiment to achieve them.
We then reassess our current conditions, update our target conditions based on what we learned, and keep going. This behavior must become habitual and pervasive. That is how we create a mindset of continuous improvement focused on ever higher levels of customer service and quality at ever lower costs.
Link para compra do livro: Lean Enterprise










![Fit for Purpose: How Modern Businesses Find, Satisfy, & Keep Customers (English Edition) por [David J Anderson, Alexei Zheglov]](https://m.media-amazon.com/images/I/41hAYWi3-OL.jpg)
![Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation (Addison-Wesley Signature Series (Fowler)) (English Edition) por [Jez Humble, David Farley]](https://m.media-amazon.com/images/I/51yF2SYUi7L.jpg)
















![Lean Enterprise: How High Performance Organizations Innovate at Scale (English Edition) por [Jez Humble, Joanne Molesky, Barry O'Reilly]](https://m.media-amazon.com/images/I/41zv2gRQh2L.jpg)